


5. Lecture et sauvegarde des données▲
Dans un premier temps vous pouvez continuer votre lecture en passant directement au paragraphe 7.1Mesure de la vitesse du son. Il est possible de revenir un peu plus tard à cette partie plus technique sur le stockage des données.
5-1. Utilisation d'un fichier CSV▲
Pour échanger, partager et analyser les données collectées lors d'une expérience, elles doivent être enregistrées dans un fichier au format informatique ouvert. Le plus utilisé est le format de fichier CSV (Comma-Separated Values). Ce type de format est en général proposé par tous les logiciels d'acquisition de données (Régressi, Latis Pro, Synchronie…) Lors de la sauvegarde, les informations contenues dans votre tableur sont transformées en un fichier texte, par opposition aux formats dits binaires. Chaque ligne de texte de votre fichier correspond alors à une ligne de votre tableur et un délimiteur comme la virgule ou le point-virgule correspondent aux séparations entre les colonnes. Les portions de texte séparées par une virgule correspondent ainsi aux contenus des cellules du tableau. La première ligne de ce fichier contient en général les titres de colonnes (grandeur mesurée en physique-chimie).
Exemple de fichier CSV
- Séparateur de colonnes : le point-virgule.
- Le # indique un commentaire contenant du texte non convertible en valeur numérique.
- La virgule est utilisée comme séparateur de la partie entière et décimale.
 |
→ |
Fichier CSV Sélectionnez |
5-2. Lire les données contenues dans un fichier CSV▲
Pour lire un fichier, ici, pas d'explorateur de fichiers, il faut indiquer à Python le répertoire dans lequel le fichier à lire se trouve. Il faut donc obtenir le répertoire par défaut dans lequel Python effectue la lecture ou l'enregistrement d'un fichier. Pour cela, on utilise le package os qui permet de gérer le système d'exploitation. Puis on demande le répertoire courant de travail.
2.
import os #operating system
print(os.getcwd()) #c=current w=working d=directory
On peut ensuite modifier le répertoire courant de travail
os.chdir("C:\chemin\_absolu\_repertoire") # Depuis de la racine
5-2-1. Le module : CSV▲
La modification est permanente, il n'est plus nécessaire d'indiquer le chemin du fichier à lire si celui-ci se trouve dans le répertoire de travail. Pour lire un fichier CSV avec Python, on utilise le package csv. Il propose un objet reader permettant de décoder un fichier CSV. L'exemple le plus simple que l'on puisse écrire est le suivant :
2.
3.
4.
5.
6.
import csv # le module pour les fichiers csv
file = open("mon_fichier.csv", "r") # ouvrir le fichier
reader = csv.reader(file, delimiter = ";") # initialisation d'un lecteur de fichier
for row in reader : # parcours du lecteur avec une boucle
print row # affichage ligne à ligne
file.close() # fermeture du fichier
Quelques précisions :
- ligne 2 : le paramètre
"r"de la fonction open impose l'ouverture du fichier en lecture seule. Dans ce cas, il n'est pas possible de modifier son contenu ; - ligne 3 : le délimiteur de colonnes est un point-virgule. Même s'il n'existe pas de spécification formelle pour l'écriture d'un fichier CSV, le séparateur par défaut est la virgule. Le point-virgule est surtout utilisé dans les pays, comme la France, où la partie décimale d'un nombre est précédée d'une virgule.
42. À l'aide d'un éditeur de texte ou d'un logiciel de gestion d'acquisition de données (LatisPro, Regressi…) élaborer un fichier CSV.
Remarques :
- Word ou Libre Office ne sont pas des éditeurs de texte, il faut utiliser Notepad sous Windows, gedit sous Linux ou TextEdit sous macOS. Attention de bien indiquer l'extension csv lors de la sauvegarde : mon_fichier.csv ;
- si vous utilisez un logiciel du type LatisPro, il y a normalement un menu permettant d'exporter vos données au format CSV.
43. Placer ensuite ce fichier dans le répertoire de travail défini avec Python, puis effectuer la lecture de ce fichier.
Attention à bien indiquer le bon symbole pour le délimiteur de colonnes.
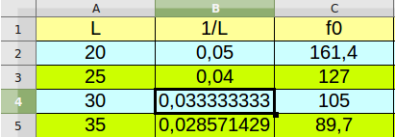
La lecture d'un fichier CSV réalisée sur LatisPro permet d'obtenir l'affichage suivant :
['Longueur onde', 'Absorbance']
['4E-7' ; '0,3287']
['4,05E-7' ; '0,3546']
['4,1E-7' ; '0,3731']L'objectif est maintenant l'exploitation des données récupérées du fichier CSV.
- On observe que chaque ligne du tableur de LatisPro est placée dans une liste Python. Or, si ces données sont destinées à tracer des graphiques avec Python, nous venons de voir que les valeurs d'une même grandeur doivent appartenir à même liste. Ce qui n'est manifestement pas le cas.
- On remarque également que toutes les valeurs sont considérées comme chaîne de caractères. Une conversion automatique des nombres est possible, mais elle ne fonctionne pas si la séparation partie entière, partie décimale est une virgule.
Il s'avère donc nécessaire d'écrire une fonction de lecture des fichiers CSV un peu moins naïve afin de tenir compte des remarques précédentes. Dans ce but, je propose ci-dessous la fonction readColCSV permettant d'extraire une colonne correspondant à la liste des valeurs de la grandeur désirée dans le fichier CSV. Cette fonction ne permettra pas de gérer tous cas de figure que vous pourriez rencontrer lors de l'utilisation de fichier CSV, mais c'est un bon point de départ que l'on peut ensuite enrichir en fonction de ses besoins.
Taper la fonction readColCSV dans une cellule du Notebook.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
def readColCSV(fichier, sep, n) :
'''
Pour les deux premiers paramètres, attention à bien utiliser les
guillemets, car la fonction attend des chaînes de caractères.
fichier <str> : le nom du fichier -> "mon_fichier.csv"
sep <str> : le séparateur des colonnes par exemple -> ";"
n <int> : le numéro de la colonne à lire
'''
file = open(fichier, "r")
reader = csv.reader(file, delimiter = sep)
col = []
for row in reader:
try:
notation_point = row[n].replace (",", ".")
col.append(float(notation_point))
except :
pass
file.close()
return col
Pour utiliser cette fonction rien de plus simple, dans une cellule du Notebook, on tape
2.
3.
# On récupère les deux premières colonnes du fichier
x = readColCSV("absorbance.csv", ";", 0)
y = readColCSV("absorbance.csv", ";", 1)
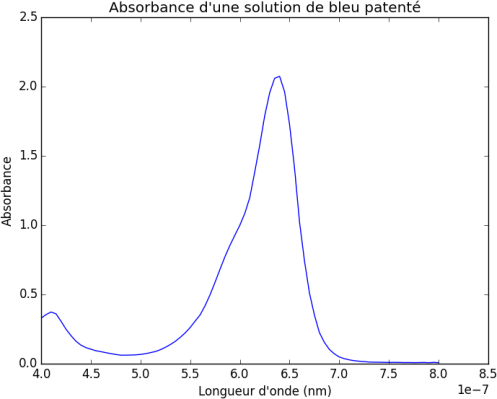
Nous pouvons ensuite tracer le graphique correspondant à kitxmlcodeinlinelatexdvpy = f (x)finkitxmlcodeinlinelatexdvp
2.
3.
4.
5.
6.
7.
8.
9.
10.
# Affichage graphique
import matplotlib.pyplot as plt # Si vous ne l'avez pas déjà chargé
%matplotlib inline # dans le même notebook
plt.plot(x, y)
plt.xlabel("Longueur d'onde (nm)")
plt.ylabel("Absorbance")
plt.title("Absorbance d'une solution de bleu patenté")
plt.savefig("absorbance.png") # permet de sauvegarder votre graphique
plt.show()
|
Attention aux caractères accentués dans les chaînes de caractères, car suivant la version Python, ils sont plus ou moins bien supportés. Pour ne pas avoir de problèmes avec les accents, il est préférable d'utiliser une version > 3. Avec les versions antérieures, il faut ajouter au début du code la ligne : |
 |
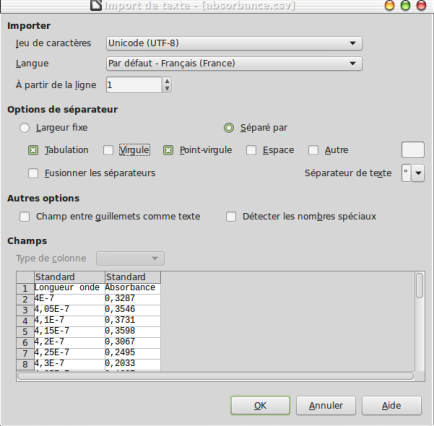 |
Pour lire les données d'un fichier CSV on peut également se servir d'un outil comme LibreOffice Calc. Au moment de l'ouverture du fichier, le logiciel propose une fenêtre permettant de choisir entre autres :
Il en est de même lors d'un enregistrement vous pouvez choisir le format CSV et indiquer le séparateur. |
5-2-2. Le module : pandas▲
Pour manipuler et analyser les données, le module pandas, développé pour Python, s'avère des plus pratique. En particulier, il permet la lecture et l'écriture de fichiers csv de manière très simplifiée. Nous le chargeons donc dès le début de notre code.
Pour ouvrir un fichier en lecture et charger les données dans la mémoire de l'ordinateur, nous utilisons la fonction read_csv du module pandas. Celle-ci reçoit plusieurs arguments parmi lesquels :
- le nom du fichier ;
- une indication sur le séparateur des données : virgule, point-virgule, espace, ou encore tabulation \t ;
- une option précisant si la première ligne du fichier est une ligne d'en-têtes ou une ligne de données.
Si nous reprenons le fichier absorbance.csv, nous pouvons écrire :
2.
3.
4.
# nom du fichier
filename = 'absorbance.csv'
# lecture des données et stockage dans la variable data
data = pd.read_csv(filename, sep = ';')
Pour avoir un aperçu du contenu (appelé dataframe), il ne reste plus qu'à écrire
data.head() # affiche les 5 premières lignes du fichier
Longueur onde Absorbance
0 4E-7 0,3287
1 4,05E-7 0,3546
2 4,1E-7 0,3731
3 4,15E-7 0,3598
4 4,2E-7 0,3067Vous remarquerez que nous avons toujours le problème de la virgule comme séparateur de la partie entière et de la partie décimale, pandas possède une fonction capable de remplacer d'un seul coup toutes les virgules en points.
2.
3.
4.
# On remplace
data = data.replace(to_replace=',', value=".", regex=True)
# On affiche
data.head()
Longueur onde Absorbance
0 4E-7 0.3287
1 4.05E-7 0.3546
2 4.1E-7 0.3731
3 4.15E-7 0.3598
4 4.2E-7 0.3067Si la première ligne du dataframe contient les intitulés des colonnes, il est possible de récupérer les données de la colonne en y faisant référence. Ne pas oublier de convertir les données sous forme de valeurs numériques avec la fonction astype('float')
2.
Lambda = data["Longueur onde"].astype('float')
Absorb = data["Absorbance"].astype('float')
44. Afficher le graphe de l'absorbance en fonction de la concentration
Dans le cas où le séparateur décimal est un point (systèmes anglo-saxons) lors de l'ouverture d'un fichier de données, pandas transforme automatiquement les chaînes de caractères en nombres entiers ou flottants suivant le contexte.
2.
3.
4.
5.
6.
# nom du fichier
filename = 'systeme_anglo_saxon.csv'
# lecture des données et stockage dans la variable data
data = pd.read_csv(filename, sep = ';')
# affichage sous forme d'un tableau
data.head()
x y
0 0.312346 1.637363
1 0.535826 2.171534
2 0.430338 1.865677
3 0.283906 1.569671
4 0.365483 1.825927print(data['x'].dtypes, data['y'].dtypes)
float64 float645-2-3. Quelques remarques utiles pour pandas▲
1. Si le fichier CSV ne possède pas d'en-tête de colonnes : on l'indique lors de la lecture du fichier avec le paramètre header et les colonnes sont affectées d'un indice entier. La première colonne possède l'indice 0, la deuxième colonne l'indice 1 et ainsi de suite.
data = pd.read_csv(filename, sep = ';', header = None)
Attention si rien n'est indiqué, ce sont les premières valeurs qui servent d'en-tête de colonnes
2. Les colonnes doivent me servir dans un calcul : il est possible d'ajouter une colonne à votre tableau (dataframe). Soit :
A B
0 1 4
1 2 5
2 3 62.
data['C'] = data['A'] * data['B']
data.head()
A B C
0 1 4 4
1 2 5 10
2 3 6 185-3. Enregistrer les données de l'acquisition dans un fichier CSV▲
5-3-1. Avec le module : CSV▲
Maintenant que nous savons lire un fichier CSV et même extraire une colonne de ce fichier, l'écriture n'est guère plus compliquée. Le module csv définit un reader pour la lecture ainsi qu’un writer pour l'écriture. Le programme minimum permettant d'écrire dans un fichier est le suivant :
Il ne reste plus qu'à écrire une fonction capable de sauvegarder les données obtenues lors de la mesure de la fréquence du stroboscope. Pour cela il faut :
- créer un fichier CSV ;
- parcourir les listes obtenues, intensite et temps, valeur par valeur ;
- ajouter la valeur pour un même indice de chaque liste comme une nouvelle ligne de notre fichier CSV.
|
Les listes Python Sélectionnez |
→ |
Le fichier CSV Sélectionnez |
La fonction writeCSV accepte en arguments deux chaînes de caractères pour le nom de fichier et le séparateur ainsi que deux listes python. Cette fonction d'écriture très simple permet de satisfaire les situations rencontrées lors de cette formation.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
def writeCSV(fichier, sep, col1, col2) :
'''
fichier <str> : le nom du fichier CSV à créer -> "mon_fichier.csv"
sep <str> : le séparateur des colonnes
col1 <list> : la première colonne -> [1, 1.5, 2, ...]
col2 <list> : la deuxième colonne -> [100, 50, 100, ...]
'''
file = open(fichier, "w")
writer = csv.writer(file, delimiter=sep)
fin1, fin2 = len(col1), len(col2)
if fin1 == fin2:
for i in range(fin1):
writer.writerow((col1[i], col2[i]))
else :
print("Les deux listes n'ont pas la même taille")
file.close()
3. Exécuter la fonction avec les listes temps et mesure de l'activité 4.4Mesure de fréquence avec capteur analogique de type photorésistor ou photodiode.
4. Ajouter deux arguments à la fonction permettant d'écrire la ligne d'en-tête (noms de colonnes) du fichier CSV.
5-3-2. Avec le module : pandas▲
Si nous reprenons l'exemple précédent avec les listes python temps et intensite, nous pouvons écrire le code suivant permettant de sauvegarder les données dans un fichier CSV.
2.
3.
4.
5.
6.
data = pd.DataFrame({
'Temps' : temps,
'Intensité' : intensite
})
filename = "mesures_intensite.csv"
data.to_csv(filename, sep=';', index=False, encoding='utf-8')
- sep
=';'indique que les informations sont séparées par un point-virgule ; - index
=Falseprécise qu'aucun indice de ligne ne doit être enregistré dans le fichier ; - encoding
='utf-8'stipule que l'encodage des données dans le fichier est utf-8.
5-3-3. Stockage des données : CLIMAT▲
De nombreux capteurs permettent d'étudier l'évolution du climat de notre planète. Ces dernières années des moyens considérables ont été déployés pour observer, mesurer, modéliser et simuler les facteurs influençant le climat de notre planète. Prenons comme exemple les interactions océan-atmosphère, plusieurs outils sont utilisés pour mesurer la température, la pression et la salinité des océans en surface et en profondeur. Les mesures sont réalisées à l'aide de sondes ou de bouées puis sont transmises grâce à une balise Argos. Pour plus de sûreté, les mesures sont aussi enregistrées sur une carte mémoire interne à la sonde ou à la bouée.
Une campagne de mesures liée à la température des océans a été réalisée à l'aide d'une sonde dérivante capable d'effectuer des cycles programmés de descente jusqu'à 2000 m de profondeur. Les caractéristiques de cette campagne sont les suivantes :
- durée de la campagne : 1 mois ;
- fréquence d'échantillonnage : 0.1 Hz.
Les relevés de la campagne de mesure sont écrits dans un fichier texte dont le contenu est défini comme suit.
Les informations relatives à la campagne se trouvent sur les deux premières lignes du fichier, on y trouve, la date, le numéro de la sonde, le numéro de la campagne, etc.
Pour chacune des lignes suivantes, on trouve la température en kelvins indiquée par 5 caractères, 1 caractère séparateur et 4 caractères pour la profondeur en mètres ainsi qu'un caractère de fin de ligne. Voici quelques exemples :
293.5,0005
...
289.7,0100
...
277.8,1500
...5. On suppose que chaque caractère est codé sur 8 bits, en ne tenant pas compte des deux premières lignes, déterminer le nombre d'octets enregistrés en une heure.
6. En déduire le nombre approximatif d'octets contenus dans le fichier de cette campagne. Une carte de 1 Go est-elle suffisante ?
